
data/dtest.lemma and
data/etest.lemma. The file you upload should have 8,714 lines.
Inflection Challenge Problem 5
The traditional formulations of the main problems in machine translation, from alignment to model extraction to decoding and through evaluation, ignore the linguistic phenomenon of morphology, instead treating all words as distinct atoms. This misses out on a number of generalizations; for example, in alignment, it could be useful to accumulate evidence across the various inflections of a verb such as walk, since walk, walked, walks, and walking all likely have related and overlapping translations.
There are two types of morphology: inflectional morphology studies how words change to reflect grammatical properties, roles, and other information, while derivational morphology describes how words changes as they are adapted to different parts of speech. Of these, inflectional morphology is the more important modeling omission in natural language generation tasks like machine translation, because choosing the right form of a word is necessary to produce grammatical output.
The inflectional morphology of English is simple. It is mostly limited to verbs and pronouns, which reflect only a subset of person, number, and one of two cases, and the forms overlap among the possible combinations. We can translate into English fairly well without bothering with morphology (an auspicious fact for the development of field).
However, this is not the case for many of the world’s languages. Languages such as Russian, Turkish, and Finnish have complex case systems that can produce hundreds of surface variations of a single lemma. The vast number of potential word forms creates data sparsity, an issue that is exacerbated by the fact that morphologically complex languages are often the ones without much in the way of parallel data.
In this assignment, you will earn an appreciation for the difficulties posed by morphology. The setting is simple: you are presented with a sequence of Czech lemmas, and your task is to choose the correct inflected form for each of them. You can imagine this as a translation task itself, except with no reordering and with a bijection between the source and target words. To support you in this task, you are provided with a parallel training corpus containing sentence pairs in both reduced and inflected forms, and a default solution chooses the most probable form for each lemma.
Getting Started
Start by cloning the assignment repo:
git clone https://github.com/mjpost/inflect
Change to the inflect directory, and type the following
to create symlinks to the training and development data (and
please observe the warning that began this section):
cd inflect
bash scripts/link_data.sh
You will then find three sets of parallel files under data:
training data (for building models), development test data
(for testing your model), and held-out test data (for
submitting to the leaderboard). Sentences
are parallel at the line level, and the words on each line
also correspond exactly across files. The parallel files
have the prefix train, dtest, and etest, and the
following suffixes:
-
*.lemmacontains the lemmatized version of the data. Each lemma can be inflected to one or more fully inflected forms (that may or may not share the same surface form). -
*.tagcontains a two-character sequence denoting each word’s part of speech -
*.treecontains dependency trees, which organize the words into a tree with words generating their arguments. The tree format is described below. -
*.formcontains the fully inflected form. Note that we providedev.formto you (the grading script needs it), but you should not look at it or build models over it.test.formis kept hidden.
You should use the development data (dtest) to test your
approaches (make sure you don’t use the answers except in
the grader). When you have something that works, you should
run it on the test data (etest) and submit that
output. The scripts/ subdirectory contains a number of
scripts, including a grader and a default implementation
that simply chooses the most likely inflection for each
word:
# Baseline: no inflection
cat data/dtest.lemma | ./scripts/grade
# Choose the most likely inflection
cat data/dtest.lemma | ./scripts/inflect | ./scripts/grade
The evaluation method is accuracy: what percentage of the correct inflections did you choose?
The Challenge
Your challenge is to improve the accuracy of the inflector as much as possible. The provided implementation simply chooses the most frequent inflection computed from the lemma alone (with statistics gathered from the training data).
For a passing grade, it is sufficient to implement a bigram language model of some form (conditioned on the previous word or lemma). However, as described above, we have provided plenty more information to you that should permit much subtler approaches. Here are some suggestions:
- Incorporate part-of-speech tags.
- Implement a bigram language model over inflected forms.
- Implement a longer n-gram model and a custom backoff structure that consider shorter contexts, POS tags, the lemma, etc.
- Train your language model on more data, perhaps pulled from the web.
- Model long-distance agreement by incorporating the labeled dependency structure. For example, you could build a bigram language model that decomposes over the dependency tree, instead of the immediate n-gram history.
- Implement multiple approaches and take a vote on each word.
Obviously, you should feel free to pursue other ideas. Morphology for machine translation is an understudied problem, so it’s possible you could come up with an idea that people have not tried before!
A note on POS tags and dependency trees
The .pos and .tree files contain parts of speech and
dependency trees for each sentence. Information about the
part-of-speech tags
can be found here.
Dependency trees are represented as follows. The tokens on each line correspond to the words they share an index with, and contain two pieces of information, depicted as PARENT/LABEL. PARENT is the index of the word’s parent word, and LABEL is the label of the edge implicit between those indices. Parent index 0 represents the root of the tree. Each child selects its parent, but the edge direction is from parent to child.
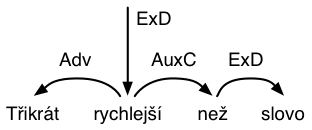
For example, consider the following lines, from the lemma, POS, tree, and word files (plus an English gloss), respectively:
třikrát`3 rychlý než-2 slovo
Cv AA J, NN
2/Adv 0/ExD 2/AuxC 3/ExD
Třikrát rychlejší než slovo
Three-times faster than-the-word
Line 3 here corresponds to the following dependency tree:
To avoid duplicated work, a class is provided to you that
will read the dependency structure for you, providing direct
access to each word’s head and children (if any), along with
the labels of these edges. Example usage can be found in
scripts/inflect-tree. For a list of analytical functions
(the edge labels),
see this document.
Ground Rules
- You can work in independently or in groups of up to three, under these
conditions:
- You must announce the group publicly on piazza.
- You agree that everyone in the group will receive the same grade on the assignment.
- You can add people or merge groups at any time before the assignment is due. You cannot drop people from your group once you’ve added them. We encourage collaboration, but we will not adjudicate Rashomon-style stories about who did or did not contribute.
- You must turn in three things:
-
The output of your inflector on both the dev and test sets (
data/dtest.lemmaanddata/etest.lemma, concatenated together), uploaded to the leaderboard submission site according to the Assignment 0 instructions. You can upload new output as often as you like, up until the assignment deadline.Your output file should have 8,714 lines.
- Your code. Send us a URL from which we can get the code and git revision history (a link to a tarball will suffice, but you’re free to send us a github link if you don’t mind making your code public). This is due at the deadline: when you upload your final answer, send us the code. You are free to extend the code we provide or roll your own in whatever langugage you like, but the code should be self-contained, self-documenting, and easy to use.
- A clear, mathematical description of your algorithm and its motivation written in scientific style. This needn’t be long, but it should be clear enough that one of your fellow students could re-implement it exactly.
-
- You should not need any other data than what we provide. You are free to use any code or software you like, except for those expressly intended to do morphological generation. If you want to use other part-of-speech taggers, syntactic or semantic parsers, machine learning libraries, thesauri, or any other off-the-shelf resources, plese feel free to do so. If you aren’t sure whether something is permitted, ask us.
Credits: This assignment was designed for this course by Matt Post. The data used in the assignment comes from the Prague Dependency Treebank v2.0